






数据有问题!

子沐研究-2025年1月30日-深究DeepSeek为什么会引起全球人工智能的关注,破解英伟达算力显卡底层的硬件程序CUDA是关键。
CUDA是英伟达公司推出的一种并行计算平台和编程模型,包括硬件和软件两部分。其工作原理是将计算任务分解为大量的并行线程,这些线程可以在 GPU 的多个核心上同时执行。开发者可以根据任务的特点,将数据和计算分配到不同的线程和线程块中,以充分利用 GPU 的并行计算能力。
当前,无论是CHAT-GPT还是抖音的豆包,都是运行在该底层程序基础之上。通俗的讲,就是DeepSeek重写CUDA,绕过了阉割版英伟达算力显卡对我国的限制,同时还提升了性能。
全球投资机构认为,英伟达通过CUDA构件的算力显卡垄断被打破,近而也打破了所有人工智能模型必须使用CUDA的垄断,更是打破了其他算力显卡公司必须依赖CUDA的垄断。近而导致英伟达的估值体系出现崩溃。
就目前来看,只有这个逻辑才能解释资本市场的变化。而市场上“成本论”虽然也有道理,但是“大力出奇迹”模式在DeepSeek出现之前,腾讯、百度、抖音都没有解决。因此,就算DeepSeek以十分之一成本达到了CHAT-GPT4.0的水平,也不会引发全球如此关注。
因为,CUDA作为英伟达核心,是 “大力出奇迹”模式的关键,而DeepSeek的突破,说明在CUDA的算法法,对算力进行了降速,或者没有全部激发算力能力。近而推动人工智能的高成本,让AI公司必须购买更多公司的产品。
这就像我们的外卖骑手和网约车司机都陷入到算法之中,而突然有一天,一位普通程序员破解了这种算法牢笼,打破了某团的垄断一样。
子沐并非硬件专家,但是也学了四年的计算机专业,学习过汇编语言和C语言的编译,同时也学习过芯片及显卡的原理。深知底层程序对于硬件设备的重要性。
发现DeepSeek绕过CUDA的是美国著名硬件媒体Tom‘s Hardware,是他们发现“DeepSeek的AI绕过行业标准CUDA,使用类似汇编的PTX编程。”

该信息也被韩国的投资机构验证。来自韩国未来资产证券(Mirae Asset Securities Research)的分析称,DeepSeek-V3的硬件效率之所以能比Meta等高出10倍,就是因为“他们从头开始重建了一切”。
在他们的这份研究报告显示,在使用英伟达的H800 GPU训练DeepSeek-V3时,在保持通信成本不变的情况下,将一次调用8个处理单元调整为13个处理单元,使得20个流处理器多单元(Streaming Multiprocessors)就足以充分利用lBand NVLink的带宽。DeepSeek采用定制的PTX(并行线程执行)指令并自动调整通信块大小,这大大减少了L2缓存f1的使用和对其他SMs的干扰。
这就相当于变相绕过了硬件对通信速度的限制。
不过,DeepSeek并没有全完绕过英伟达的CUDA,只是使用了英伟达的PTX(Parallel Thread Execution)语言重新实现了算力分配。
PTX语言接近汇编语言,允许进行细粒度更细的硬件调度,优化底层算法。但是这种编程非常复杂且难以维护,所以行业通用的做法才是使用CUDA这样的高级编程语言。
为什么是幻方量化?
有投资者不明白,为什么是一家量化投资机构重写了CUDA?
其实这个问题很容易回答,因为幻方量化公司本身就是从事A股市场高频交易的量化投资机构。这种交易模式在时间上必须追求极致,才能达到收割普通投资者的目的,也才能实现每秒400笔以上的交易策略。因此追求最快的时间,是该公司的核心文化。也正是这种公司文化才会做出直接跳过CUDA使用PTX的决策。
DeepSeek这种行为说明,任何一家生产算力显卡的公司都还有机会推出资金的CUDA,尤其是我国市场,华为昇腾系列、 摩尔线程的MTT、天数智芯的天垓和智铠系列、海光的K系列、寒武纪的MLU系列、景嘉微JM系列、比特大陆算丰系列、中科曙光DCU系列等都还有机会挑战英伟达的垄断。
目前,DeekSeek已经与AMD、华为等团队紧密合作,第一时间提供了对其他硬件生态的支持。
DeepSeek真的绕过了CUDA?
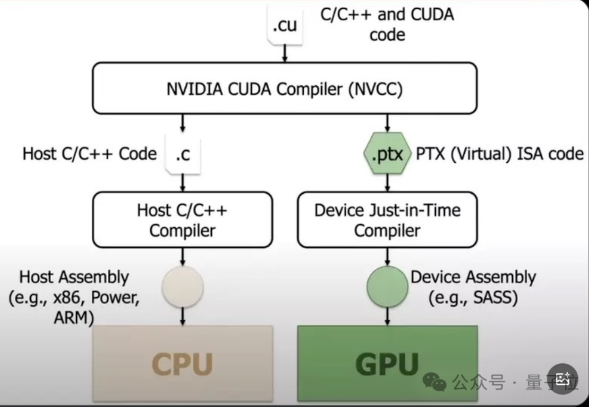
首先要明确的是,PTX仍然是英伟达GPU架构中的技术,它是CUDA编程模型中的中间表示,用于连接CUDA高级语言代码和GPU底层硬件指令。
PTX类似汇编语言,代码大概长这样:

在实际编译流程中,CUDA代码首先被编译为PTX代码,PTX代码再被编译为目标GPU架构的机器码(SASS,Streaming ASSembler)。
CUDA起到了提供高级编程接口和工具链的作用,可以简化开发者的工作。而PTX作为中间层,充当高级语言和底层硬件之间的桥梁。
另外,这种两步编译流程也使得CUDA程序具有跨架构的兼容性和可移植性。
反过来说,像DeepSeek这种直接编写PTX代码的做法,首先不仅非常复杂,也很难移植到不同型号的GPU。
有从业者表示,针对H100优化的代码迁移到其他型号上可能效果打折扣,也可能根本不工作了。
所以说,DeepSeek做了PTX级别的优化不意味着完全脱离了CUDA生态,但确实代表他们有优化其他GPU的能力。
最新消息显示,外国极客已经在树莓派单片机上正常运行DeepSeek离线大模型,证明在任何芯片上面都可以运行,哪怕是一台单片机,几百美元的都可以使用,那么对于资本市场来说,英伟达拿什么维持垄断和高估值呢?
目前,DeepSeek自研架构的代码和论文已在GitHub/arXiv开源,训练日志在官方平台可查。
以上内容借鉴了华尔街见闻的观点。
参考链接:
[1]https://www.tomshardware.com/tech-industry/artificial-intelligence/deepseeks-ai-breakthrough-bypasses-industry-standard-cuda-uses-assembly-like-ptx-programming-instead
[2]https://x.com/bookwormengr/status/1883355712191123666
[3]https://tinkerd.net/blog/machine-learning/cuda-basics/
[4]https://www.amd.com/en/developer/resources/technical-articles/amd-instinct-gpus-power-deepseek-v3-revolutionizing-ai-development-with-sglang.html
[5]https://x.com/ggerganov/status/1883888097185927311
数据有问题!
这他妈的是啥东西,胡咧咧
密码保护
美国这是着急了,应该还会有动作。
不知道这6万亿来自哪里?是不是供应链金融…
如果你说的是对的,那英伟达的利益集团将疯狂攻击DeepSeek